Introduction
“Testing gives you confidence. Proof gives you a guarantee.”
Problem. Code can be tested, but testing never exhausts all inputs—every passing test suite still leaves room for subtle logical errors and specification violations. Formal verification closes this gap by constructing machine-checkable proofs that an implementation satisfies its specification for all possible inputs. We study this problem in Lean 4, a modern interactive theorem prover, where the goal is to automatically generate such proofs for realistic programs.
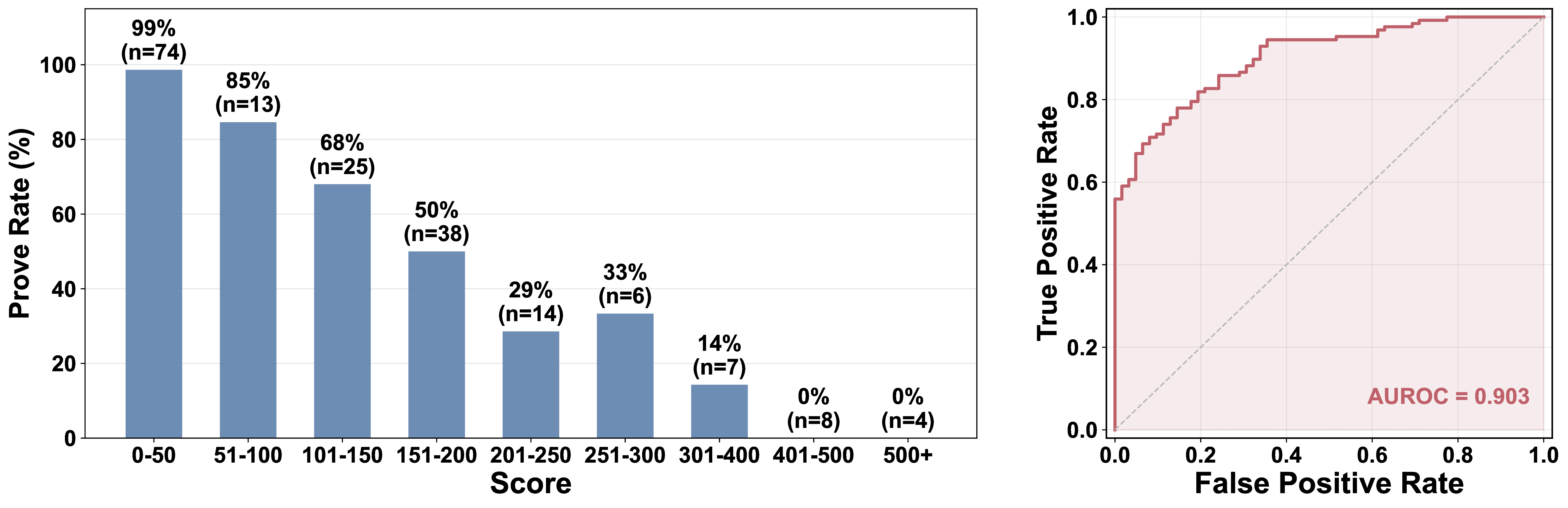
Method. We propose a hierarchical proof search framework built around two stages: recursive lemma decomposition, which iteratively breaks a complex verification goal into simpler, independently provable subgoals until each is tractable, and iterative lemma completion, which solves each leaf subgoal through proof search with compiler feedback. A principled decomposition score drives both stages—guiding candidate selection at inference and serving as a dense reward signal during training.
Model & Release. We train a single unified model, Göedel-Code-Prover-8B, for both decomposition and completion via supervised initialization followed by hybrid reinforcement learning. We publicly release the model weights and an evaluation framework to support future research in automated code verification.
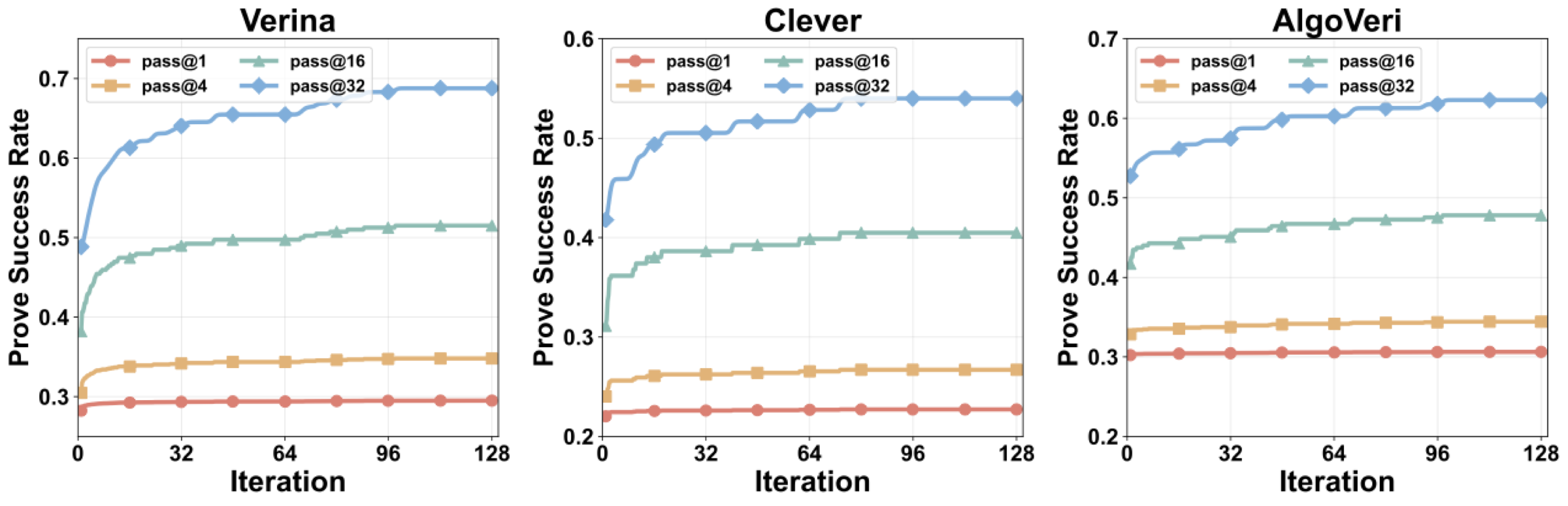
Results. Göedel-Code-Prover-8B achieves prove success rates of 68.8%, 54.0%, and 62.3% across three Lean 4 code verification benchmarks, for an overall rate of 62.0%—a 2.6× improvement over the strongest baseline. Among frontier reasoning models, the best performer (GPT-5.3-Codex) reaches only 18.5%; among neural provers, DeepSeek-Prover-V2-671B and Goedel-Prover-V2-32B achieve 21.8% and 21.5% respectively. With only 8B parameters, our model surpasses all of them, including provers 4–84× its size.

Note: Baselines use parallel whole-proof generation (Pass@128), while our framework employs search-based hierarchical inference—a fundamentally different inference paradigm enabled by our trained decomposition and completion pipeline. This comparison reflects end-to-end system-level performance. Even scaling open-source provers to significantly larger budgets shows diminishing returns (see paper for details), suggesting that the gap is not merely a matter of compute allocation.